AME - Escuela de Ciencia de Datos
Septiembre 2019
Historias con Impacto a Través de la
Ciencia de Datos
Vianey Leos(-)Barajas
Depts of Forestry & Envir. Resources and Statistics
North Carolina State University
Historias con Impacto
The biggest impact we can have is when we make discoveries about the world we live in.

What Story Do We Want Tell?
This is usually the easier part -- there are so many cool questions we can try to answer with data!
Some examples:
- How do white sharks react to tourism boats?

- How can we personalize (clothing/videos/products)? Check out StitchFix's algorithms team.

Quantifying the behavior we want to observe
Real World (of Mexican sharks)

Full Video: Pelagios Kakunjá YouTube Channel
Source: Pelagios Kakunjá
Quantifying the behavior we want to observe
Real World (of Mexican sharks)
Full Video: Pelagios Kakunjá YouTube Channel
Source: Pelagios Kakunjá
Quantified World
May be able to detect the shark's presence (if tagged)
Can not record the presence of untagged animals
Surface currents may be available
Temperature
A lot of information can not be recorded
White Shark Movements
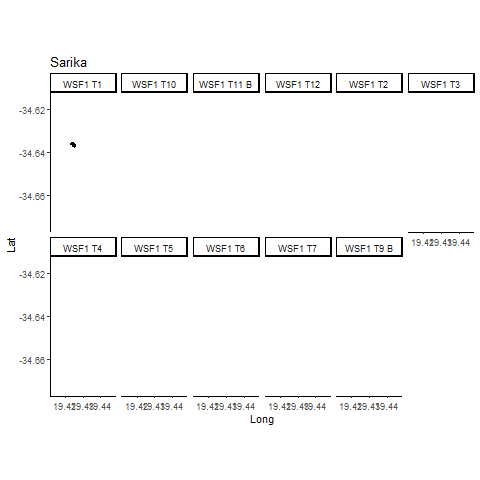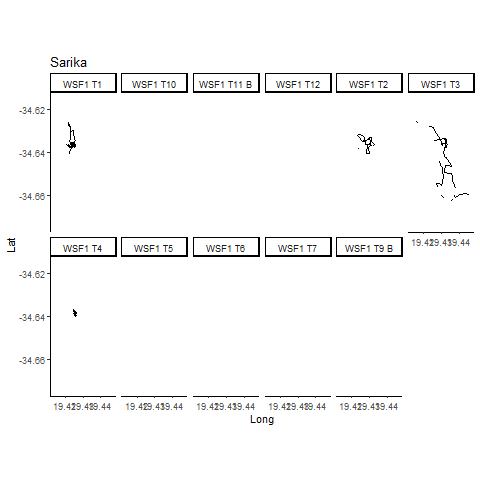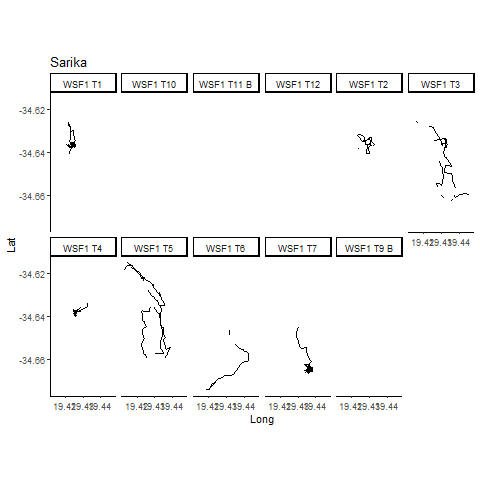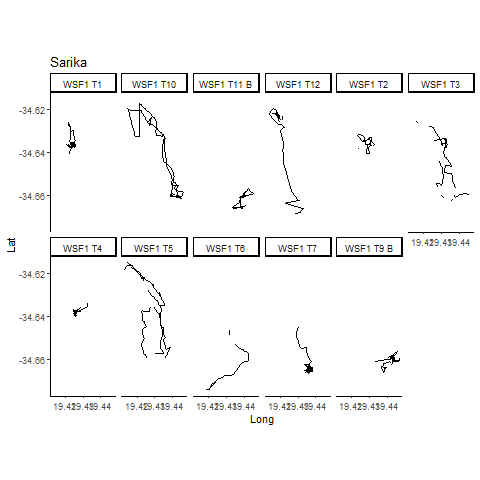
Data collected by Alison Towner.
Bull Shark Movements
Work with Pelagios Kakunjá.
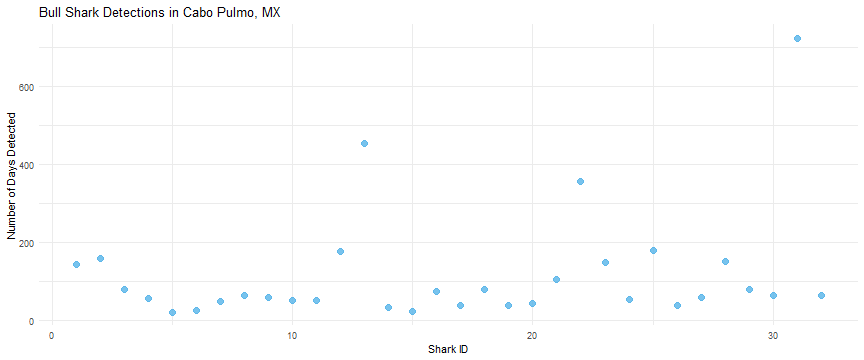
For more shark work: check out MigraMar and Alex Hearn.
Data Organization and Manipulation
Organization
Organizing and structuring your data set is one of the most important aspects in any project.
Manipulation
Writing scripts to go from the raw data set to the formatted data set for analysis. In R, take a look at the tidyverse.
What models are seen as...

How we should think of models...

The story of SLR
What does it actually mean?
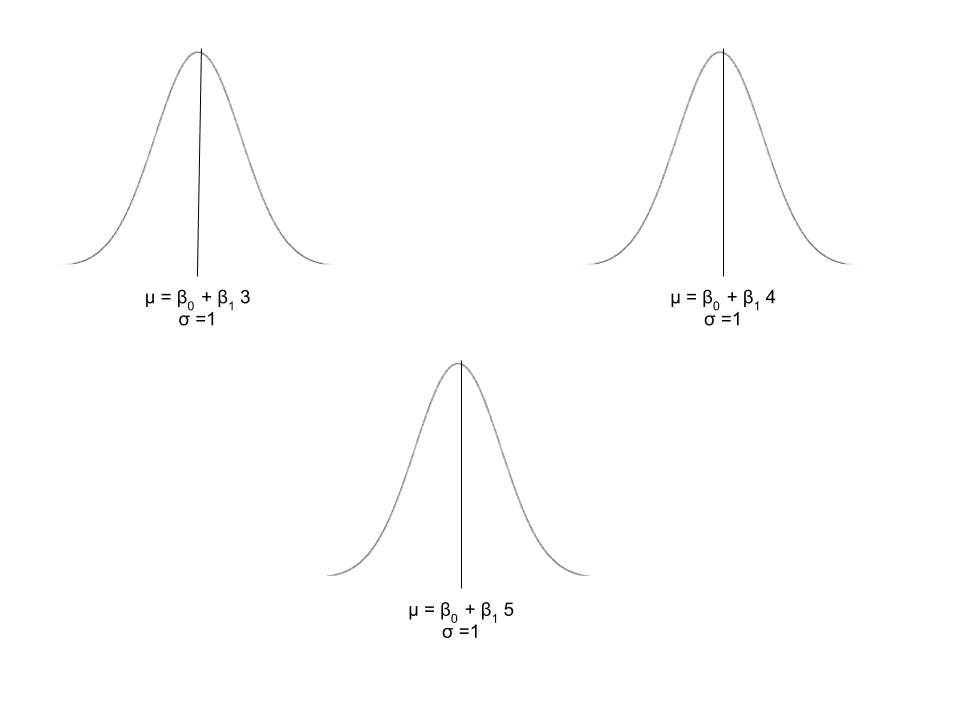
The means under different values of are connected (they're friends on a line.)
Simulating Data from a SLR
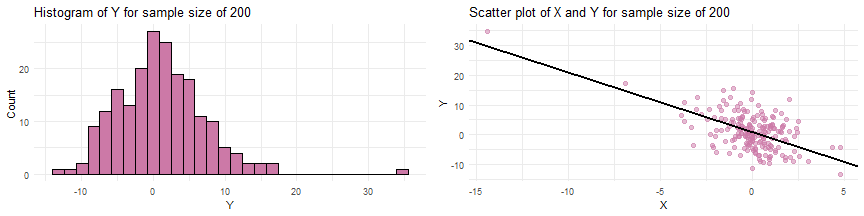
#R Codeset.seed(17)beta0 <- 1beta1 <- 2std.dev <- 5x <- rt(n = 150, df = 3) y <- beta0 + beta1*x + rnorm(n=150, mean = 0, sd=std.dev)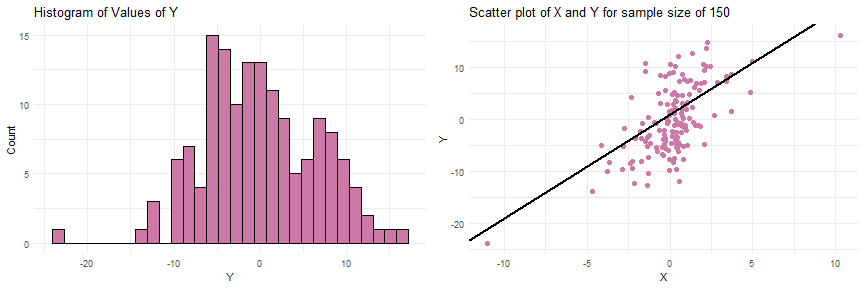
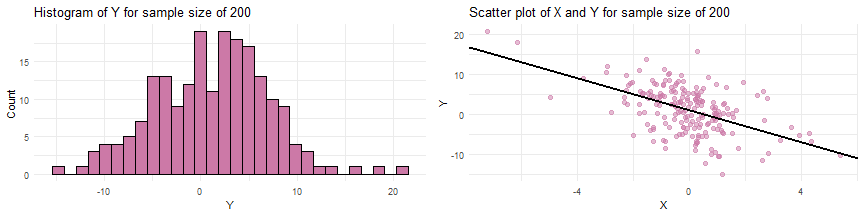
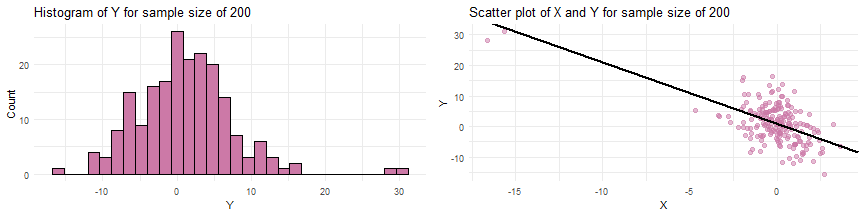
Simulating data from a SLR when the sample size
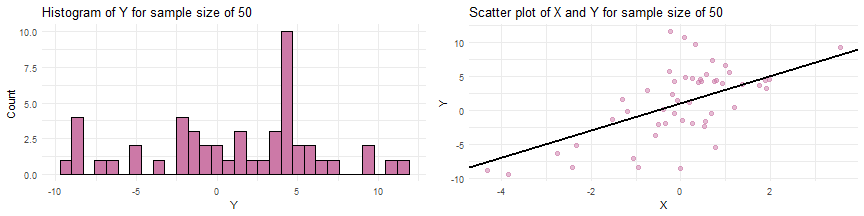
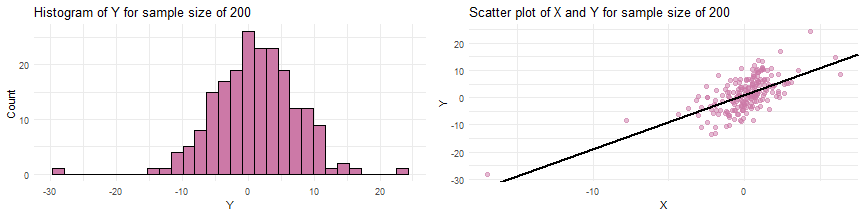
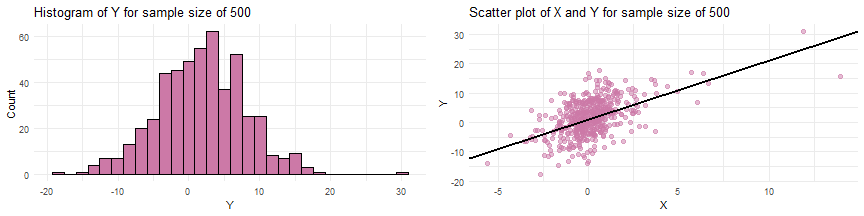
Simulating data from a SLR when the sample size of and parameter values of
Generalized Linear Model: Poisson Log-Linear Model
Here, we imply that:
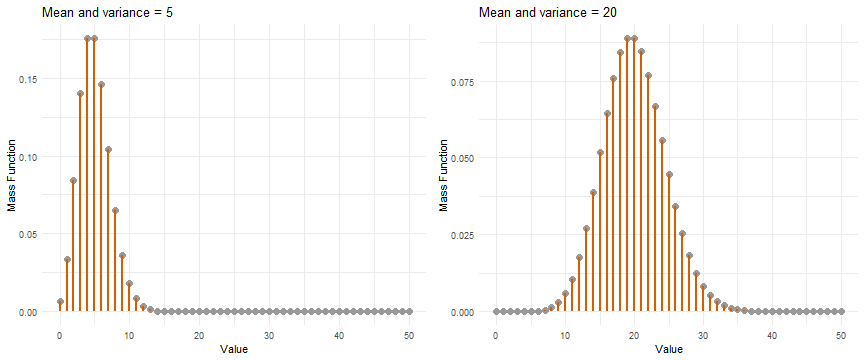
A special property of the Poisson distribution is that .
Poisson distribution with :
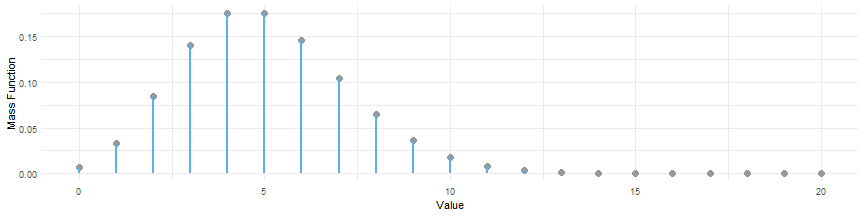
The story of the Poisson Log-Linear Model
For every value of , we expect to see observations that are generated according to the Poisson distribution with .
Simulating from a Poisson Log-Linear Model
pbeta0 <- 0.1pbeta1 <- 0.2px <- runif(n=100, min=-5, max=5)xlambda <- exp(pbeta0 + pbeta1*px)py <- rpois(n=100, lambda=xlambda)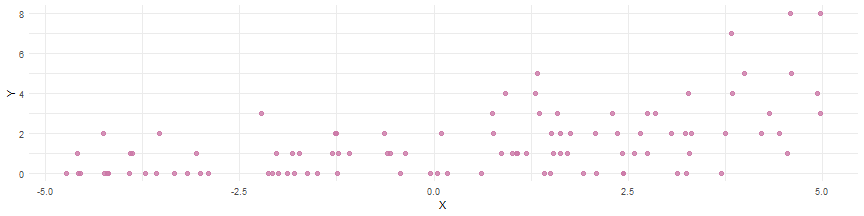
Simulating from a Hierarchical Model
## 10 individualspb0h <- rnorm(n = 10, mean = 0.1, sd = 0.1)pb1h <- rnorm(n=10, mean=0.2, sd=0.1)pxh <- matrix(data=NA, nrow=10, ncol=20) pyh <- matrix(data=NA, nrow=10, ncol=20)for(j in 1:10){ pxh[j,] <- runif(n=20, min=-5, max=5) pyh[j,] <- rpois(n=20, lambda=exp(pb0h[j] + pb1h[j]*pxh[j,]))}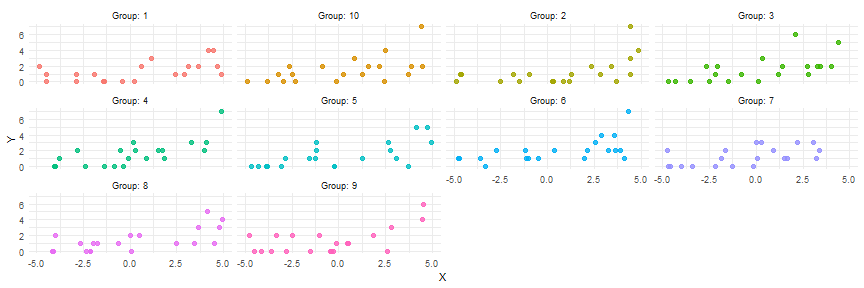
Fitting models to data
It's one thing to think about the wonderful stories that models to tell. And another thing to face the reality of trying to fit these models to data.
Some models are well-behaved with small data sets...

Fitting models to data
It's one thing to think about the wonderful stories that models to tell. And another thing to face the reality of trying to fit these models to data.
Some models are well-behaved with small data sets...
Some models are data hungry...

Historias con Impacto
The biggest impact we can have is when we make discoveries about the world we live in.